let name = "Levi";
let age = 25;ADT & Pattern Matching
Algebraic Data Types
What is that thing?
It sounds fancy, but it’s just a way to define a new type in terms of other types.
But why not just call it a “composite type”? Well, the term “algebraic data type” comes from the fact that these types can be thought of as solutions to algebraic equations. i.e. we can create a new type by combining other types using operations like addition and multiplication.
We’ll see what that means in a bit.
There are two main kinds of algebraic data types: product types and sum types.
Product Type
Product Type is a type that contains multiple values, each with its own type.
What are they? You may have already seen them in the form of tuples, structs, array, etc.
Basically they are just a collection of values. And if we wish, we can represent them all as a tuple.
Let’s start from a primitive types:
Adding more info…
let name = "Levi";
let age = 25;
let gender = "Male";
let address = "1234 Main St";
let city = "San Francisco";
let state = "CA";It looks a lot, let’s group some of them into a tuple:
let name = "Levi";
let age = 25;
let gender = "Male";
// tuple
let address = ("1234 Main St", "San Francisco", "CA");Grouping further…
let person = ("Levi", 25, "Male", ("1234 Main St", "San Francisco", "CA"));How to get the age of a person? Just access the second element of the tuple!
fn get_age(person: (&str, i32, &str, (&str, &str, &str))) -> i32 {
person.1
}
fn get_gender(person: (&str, i32, &str, (&str, &str, &str))) -> String {
person.2.to_string()
}
println!("age: {}", get_age(person));
println!("gender: {}", get_gender(person));age: 25
gender: MaleNamed tuple == struct
A tuple is a very simple form of a product type. But it’s not very readable, isn’t it?
We can create a struct to give names to the fields:
struct Person {
name: String,
age: i32,
gender: String,
address: Address,
}
struct Address {
street: String,
city: String,
state: String,
}
fn main() {
// this is similar to
// let person = ("Levi", 25, "Male", ("1234 Main St", "San Francisco", "CA"));
let person = Person {
name: "Levi".to_string(),
age: 25,
gender: "Male".to_string(),
address: Address {
street: "1234 Main St".to_string(),
city: "San Francisco".to_string(),
state: "CA".to_string(),
},
};
println!("name: {}", person.name);
println!("age: {}", person.age);
}
main();name: Levi
age: 25That’s a lot more readable! But essentially, it’s the same thing as a tuple.
Long tuple == array
Now, let’s make more persons:
// get names of two persons
fn get_names(person_1: &Person, person_2: &Person) -> (String, String) {
(person_1.name.clone(), person_2.name.clone())
}
fn main() {
// create two persons
let person_1 = Person {
name: "Levi".to_string(),
age: 25,
gender: "Male".to_string(),
address: Address {
street: "1234 Main St".to_string(),
city: "San Francisco".to_string(),
state: "CA".to_string(),
},
};
let person_2 = Person {
name: "Eren".to_string(),
age: 24,
gender: "Male".to_string(),
address: Address {
street: "5678 Main St".to_string(),
city: "San Francisco".to_string(),
state: "CA".to_string(),
},
};
let names = get_names(&person_1, &person_2);
println!("names: {:?}", names);
}
main();names: ("Levi", "Eren")How about if we have 100 persons?
Do we need to define 100 variables? No, of course we can use an array (vec in Rust)
fn get_names(person: &Vec<Person>) -> Vec<String> {
// loop through each person and get their name
person.iter().map(|p| p.name.clone()).collect()
}
fn main() {
// people == array of persons
let people = vec![
Person {
name: "Levi".to_string(),
age: 25,
gender: "Male".to_string(),
address: Address {
street: "1234 Main St".to_string(),
city: "San Francisco".to_string(),
state: "CA".to_string(),
},
},
Person {
name: "Eren".to_string(),
age: 24,
gender: "Male".to_string(),
address: Address {
street: "5678 Main St".to_string(),
city: "San Francisco".to_string(),
state: "CA".to_string(),
},
}
];
let names = get_names(&people);
println!("names: {:?}", names);
}
main();names: ["Levi", "Eren"]Cool! But that’s essentially the same thing as this tuple:
let people = (
("Levi", 25, "Male", ("1234 Main St", "San Francisco", "CA")),
("Eren", 24, "Male"), ("5678 Main St", "San Francisco", "CA"));
println!("{:?}", people);(("Levi", 25, "Male", ("1234 Main St", "San Francisco", "CA")), ("Eren", 24, "Male"), ("5678 Main St", "San Francisco", "CA"))But yes the tuple one is not easily readable. Array helps us to group the same type of data.
Cardinality
The number of possible values of a product type is the product of the number of possible values of each of its components.
For example, if we have a product type with two fields, one of which can take 3 values and the other can take 4 values, then the product type can take 3 * 4 = 12 values.
animals = ["cat", "dog", "fish"] // -> 3
colors = ["red", "green", "blue", "yellow"] // -> 4
// Tuples
animals_colors = (animals, colors) // -> 3 * 4 = 12
// there are 12 possible pairs of animals and colors
// Struct
struct Zoo {
animal: String, // -> 3
color: String, // -> 4
} // -> 12
// Array
animals = [animals, // 3
animals // 3
] // -> 3 * 3 = 9So, as the name implies, a product type is like a product (*) in mathematics. The number of possible values of a product type is the product of the number of possible values of each of its components.
Remember this concept, we will see it again later.
Sum Type
Sum types are types that can have different forms. They are also called “tagged unions” or “variants”
They are a way to define a type that can be one of several different things.
enum Role {
Admin,
User,
Guest,
}
struct Person {
name: String,
role: Role,
}
fn main() {
let levi = Person {
name: "Levi".to_string(),
role: Role::Admin,
};
let eren = Person {
name: "Eren".to_string(),
role: Role::User,
};
}A role can be either an Admin, a User, or a Guest.
We can then use it like this:
fn can_access_restricted_content(person: &Person) -> bool {
match person.role {
Role::Admin => true,
Role::User => true,
Role::Guest => false,
}
}Constant
You may ask, can we just represent a sum type by using a constant?
Yes, we can. But it’s not recommended because it’s not type-safe
const ADMIN: &'static str = "Admin";
const USER: &'static str = "User";
const GUEST: &'static str = "Guest";
struct Person {
name: String,
// use the constants
role: &'static str,
}
fn main() {
let levi = Person {
name: "Levi".to_string(),
// a string constant
role: ADMIN,
};
let eren = Person {
name: "Eren".to_string(),
role: USER,
};
let armin = Person {
name: "Armin".to_string(),
role: GUEST,
};
}But what prevent someone to assign a wrong value?
let mikasa = Person {
name: "Mikasa".to_string(),
role: "TITAN" //this WILL still compile. But "TITAN" is not a valid role
};Moreover, since those contants are not explicitly grouped, it’s harder to know what values are possible.
We would end up adding comments to explain it or adding prefixes to the constant names or put them inside namespaces, e.g.:
const ROLE_ADMIN: &'static str = "Admin";
const ROLE_USER: &'static str = "User";
const ROLE_GUEST: &'static str = "Guest";And the major downside is that we loss the safety of pattern matching
fn can_access_restricted_content(person: &Person) -> bool {
match person.role {
ROLE_ADMIN => true,
ROLE_USER => true,
// if we forget to add this, the code will STILL compile
// ROLE_GUEST => false,
_ => true,
}
}let armin = Person {
name: "Armin".to_string(),
role: GUEST,
};
// we want it to be false, but it will be true
can_access_restricted_content(&armin)trueAttaching Additional Data
What if we need to store additional data for each role? i.e. not only a constant but also with some data
For example, a chat can be either: - a text message: contains a string - an image: contains a URL and a caption - a video: contains a video URL and a thumbnail URL
How to model that?
Tagged Struct
Let’s try in Python, we define structs with a tag field (type)
Then, whenever we want to process a message, we check the tag field to know what kind of message it is
class TextMessage:
def __init__(self, text):
# tag field
self.type = "Text"
self.text = text
class ImageMessage:
def __init__(self, url, caption):
self.type = "Image"
self.url = url
self.caption = caption
class VideoMessage:
def __init__(self, video_url, thumbnail_url):
self.type = "Video"
self.video_url = video_url
self.thumbnail_url = thumbnail_url
# Create a function to process messages
def process_message(message):
# check the tag field
message_type = message.type
if message_type == "Text":
print(f"Text message: {message.text}")
elif message_type == "Image":
print("Image message:")
print(f"URL: {message.url}")
print(f"Caption: {message.caption}")
elif message_type == "Video":
print("Video message:")
print(f"Video URL: {message.video_url}")
print(f"Thumbnail URL: {message.thumbnail_url}")
else:
print("Unknown message type")
# Example usage
text_message = TextMessage("Hello, world!")
image_message = ImageMessage(
"https://example.com/image.jpg", "A beautiful sunset")
video_message = VideoMessage(
"https://example.com/video.mp4", "https://example.com/thumbnail.jpg")
process_message(text_message)
process_message(image_message)
process_message(video_message)Class
Why do we need to store type field? Can we just use the class? Anyway, class inherently has a type
# Define classes for each message type
class TextMessage:
def __init__(self, text):
# no more tag field
self.text = text
class ImageMessage:
def __init__(self, url, caption):
self.url = url
self.caption = caption
class VideoMessage:
def __init__(self, video_url, thumbnail_url):
self.video_url = video_url
self.thumbnail_url = thumbnail_url
def process_message(message):
# use isinstance to check the type of the object
if isinstance(message, TextMessage):
print(f"Text message: {message.text}")
elif isinstance(message, ImageMessage):
print("Image message:")
print(f"URL: {message.url}")
print(f"Caption: {message.caption}")
elif isinstance(message, VideoMessage):
print("Video message:")
print(f"Video URL: {message.video_url}")
print(f"Thumbnail URL: {message.thumbnail_url}")
else:
print("Unknown message type")
# Example usage
text_message = TextMessage("Hello, world!")
image_message = ImageMessage(
"https://example.com/image.jpg", "A beautiful sunset")
video_message = VideoMessage(
"https://example.com/video.mp4", "https://example.com/thumbnail.jpg")
process_message(text_message)
process_message(image_message)
process_message(video_message)This is exactly how we model a sum type in languages that don’t have built-in support for sum types. We use classes to represent the different forms of the sum type, and we use the type of the object to determine which form it is.
In OOP, we can further improve the code by using polymorphism (i.e. create a base class, move process_message method to the base class, so that we can getting rid of the if-else statement)
Let’s try that in Golang:
package main
import "fmt"
// Define an interface for the message
type Message interface {
process()
}
// Define structs for each message type
type TextMessage struct {
Text string
}
type ImageMessage struct {
URL string
Caption string
}
type VideoMessage struct {
VideoURL string
ThumbnailURL string
}
// Implement the process method for each message type
func (m TextMessage) process() {
fmt.Printf("Text message: %s\n", m.Text)
}
func (m ImageMessage) process() {
fmt.Println("Image message:")
fmt.Printf("URL: %s\n", m.URL)
fmt.Printf("Caption: %s\n", m.Caption)
}
func (m VideoMessage) process() {
fmt.Println("Video message:")
fmt.Printf("Video URL: %s\n", m.VideoURL)
fmt.Printf("Thumbnail URL: %s\n", m.ThumbnailURL)
}
// Create a function to process messages
func processMessage(message Message) {
// no more if else, just call the process method
message.process()
}
func main() {
// Example usage
textMessage := TextMessage{Text: "Hello, world!"}
imageMessage := ImageMessage{
URL: "https://example.com/image.jpg",
Caption: "A beautiful sunset",
}
videoMessage := VideoMessage{
VideoURL: "https://example.com/video.mp4",
ThumbnailURL: "https://example.com/thumbnail.jpg",
}
processMessage(textMessage)
processMessage(imageMessage)
processMessage(videoMessage)
}Rust Enum
Before we see Rust’s Enum, let’s see how Enum is used in another language, Python:
from enum import Enum
# Define an enum for different message types
class MessageType(Enum):
TEXT = 1
IMAGE = 2
VIDEO = 3Enum in Python only contains constants, it doesn’t have any data. But in Rust, Enum can have additional data
enum Message {
Text(String), // it contains a String
Image(String, String), // it contains two Strings
Video(String, String), // it contains two Strings
}
Message::Text("Hello".to_string());
Message::Image("https://example.com/image.jpg".to_string(), "A beautiful image".to_string());…or named field (so that it’s clearer what the data represents)
enum Message {
Text(String),
Image { url: String, caption: String }, // still contains two Strings, but clearer what they are
Video { video_url: String, thumbnail_url: String },
}
Message::Text("Hello".to_string());
Message::Image {
url: "https://example.com/image.jpg".to_string(),
caption: "A beautiful image".to_string(),
};Let’s rewrite the previous example in Rust:
// Define an enum for different message types
enum Message {
Text(String),
Image { url: String, caption: String },
Video { video_url: String, thumbnail_url: String },
}
// Create a function to process messages
fn process_message(message: &Message) {
match message {
// Pattern Matching ftw!
Message::Text(text) => println!("Text message: {}", text),
Message::Image { url, caption } => {
println!("Image message:");
println!("URL: {}", url);
println!("Caption: {}", caption);
}
Message::Video { video_url, thumbnail_url } => {
println!("Video message:");
println!("Video URL: {}", video_url);
println!("Thumbnail URL: {}", thumbnail_url);
}
}
}
fn main() {
// Example usage
let text_message = Message::Text("Hello, world!".to_string());
let image_message = Message::Image {
url: "https://example.com/image.jpg".to_string(),
caption: "A beautiful sunset".to_string(),
};
let video_message = Message::Video {
video_url: "https://example.com/video.mp4".to_string(),
thumbnail_url: "https://example.com/thumbnail.jpg".to_string(),
};
process_message(&text_message);
process_message(&image_message);
process_message(&video_message);
}Compare it to Golang and Python example, arguably Rust’s Enum is the most concise and readable
Pattern Matching
We have seen pattern matching in action, but we haven’t talked about it yet.
Think of pattern matching as a more powerful version of a switch statement. It allows you to match on the structure of data and bind variables to parts of that structure.
There are some properties of pattern matching which make it very powerful:
Exhaustiveness
Pattern matching is exhaustive, which means that you have to handle all possible cases. If you don’t, the compiler will give you an error.
enum Message {
Text(String),
Image { url: String, caption: String },
Video { video_url: String, thumbnail_url: String },
}Let’s say we only handle Text message:
fn process_message(message: &Message) {
match message {
Message::Text(_) => println!("Text message"),
}
}[E0004] Error: non-exhaustive patterns: `&Message::Image { .. }` and `&Message::Video { .. }` not covered ╭─[command_7:1:1] │ 2 │ match message { │ ───┬─── │ ╰───── patterns `&Message::Image { .. }` and `&Message::Video { .. }` not covered 3 │ Message::Text(_) => println!("Text message"), │ │ │ ╰─ help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern, a match arm with multiple or-patterns as shown, or multiple match arms: `, &Message::Image { .. } | &Message::Video { .. } => todo!()` ───╯
See, the compiler complains (for a good reason). Let’s fix it
fn process_message(message: &Message) {
match message {
Message::Text(_) => println!("Text message"),
Message::Image{..} => println!("Image message"),
Message::Video{..} => println!("Video message"),
}
}It now can compile.
We could also use _ to match all other cases. It’s like a wildcard/default case in a switch statement
fn process_message(message: &Message) {
match message {
Message::Text(_) => println!("Text message"),
_ => println!("Non-text message"),
}
}Using _ is generally discouraged because it defeats the purpose of pattern matching, which is to make sure you handle all possible cases.
But sometimes you really don’t care about some cases, and _ can be useful in those situations.
Destructuring
Pattern matching can also be used to destructure data. This is useful when you want to extract parts of a complex data structure.
fn process_message(message: &Message) {
match message {
// destructuring the text
Message::Text(text) => println!("Text message: {}", text),
// destructuring the image url and caption
Message::Image{url, caption} => {
println!("Image message");
// we then can use the url and caption like a normal variable
println!("URL: {}", url);
println!("Caption: {}", caption);
Message::Video{video_url, thumbnail_url} => {
println!("Video message");
println!("Video URL: {}", video_url);
println!("Thumbnail URL: {}", thumbnail_url);
}
}
}Guard Clause
Pattern matching can also have a guard clause, which is an additional condition that must be true for the pattern to match.
fn process_message(message: &Message) {
match message {
// guard clause: only match if the text is longer than 100 characters
Message::Text(text) if text.len() > 100 => println!("Long text message: {}", text),
Message::Image{..} => println!("Image message"),
Message::Video{..} => println!("Video message"),
}
}[E0004] Error: non-exhaustive patterns: `&Message::Text(_)` not covered ╭─[command_11:1:1] │ 2 │ match message { │ ───┬─── │ ╰───── pattern `&Message::Text(_)` not covered │ 6 │ Message::Video{..} => println!("Video message"), │ │ │ ╰─ help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown: `, &Message::Text(_) => todo!()` ───╯
The compiler knows that the guard clause is not exhaustive, it give an error if you don’t handle all possible cases.
Let’s handle that
fn process_message(message: &Message) {
match message {
// guard clause: only match if the text is longer than 100 characters
Message::Text(text) if text.len() > 100 => println!("Long text message: {}", text),
// other text messages
Message::Text(text) => println!("Short text message: {}", text),
Message::Image{..} => println!("Image message"),
Message::Video{..} => println!("Video message"),
}
}The combination of enum + pattern matching is very powerful. It allows you to define complex data structures and then work with them in a very concise and readable way.
We will see more examples of this in the next sections.
Cardinality
What is the cardinality of a sum type?
Yes, as the name implies, it’s the sum of the cardinality of each variant
colors = ["red", "green", "blue", "yellow"] // -> 4
enum Animal {
Cat{colors} // -> 4
Zebra // -> 1
Dog{colors} // -> 4
} // -> 4 + 1 + 4 = 9Why sum? Because either the value is a Cat, a Zebra, or a Dog. It can’t be more than one at the same time.
Common Types
Let’s see common ADTs in Rust (they also commonly found in other languages supporting ADTs)
Option
Option/Maybe is a sum type that represents either having a value or not having a value.
// generic type is generally used
// for simplicity we will use i32
enum Maybe {
Some(i32), // contains an i32 value
Nothing, // contains nothing
}
fn divide(numerator: i32, denominator: i32) -> Maybe {
if denominator == 0 {
Maybe::Nothing
} else {
Maybe::Some(numerator / denominator)
}
}
fn main() {
let result = divide(10, 2);
// check if the result is a Some or a Nothing
match result {
Maybe::Some(value) => println!("result: {}", value),
Maybe::Nothing => println!("cannot divide by zero"),
}
}
main();result: 5So what’s the benefit of using a Maybe type?
- No more
nullpointer exception (we will later why it’s a bad thing) - Explicitly handle the case when the value is missing (otherwise the compiler will complain)
- Can be chained together -> no more
ifstatement
Btw Rust has a built-in Option type, similar to our Maybe type. So, let’s use it instead
#[derive(Debug)]
struct User {
username: String,
id: i32,
}
#[derive(Debug)]
struct Post {
user_id: i32,
title: String,
content: String,
}
// the return is Option, indicating that it may or may not return a value
fn get_user(user_db: &Vec<User>, id: i32) -> Option<&User> {
user_db.iter().find(|u| u.id == id)
}
// Option result also
fn get_post(post_db: &Vec<Post>, id: i32) -> Option<&Post> {
post_db.iter().find(|p| p.user_id == id)
}
fn main() {
let user_db =vec![User {
username: "levi".to_string(),
id: 1,
}];
let post_db = vec![Post {
user_id: 1,
title: "Hello, world".to_string(),
content: "This is my first post".to_string(),
}];
let user = get_user(&user_db, 1);
// this will be error
// no field `id` on type `Option<&User>`
let post = get_post(&post_db, user.id);
}
main()[E0609] Error: no field `id` on type `Option<&User>` ╭─[command_5:1:1] │ 38 │ let post = get_post(&post_db, user.id); │ ┬┬ │ ╰─── help: one of the expressions' fields has a field of the same name: `unwrap().` │ │ │ ╰── unknown field ────╯
To resolve that compile error, we have to explicitly handle the case when the value is missing
Notice that this is compile error, not runtime error
fn main() {
let user_db =vec![User {
username: "levi".to_string(),
id: 1,
}];
let post_db = vec![Post {
user_id: 1,
title: "Hello, world".to_string(),
content: "This is my first post".to_string(),
}];
let user = get_user(&user_db, 1);
match user {
// the user may or may not exist
Some(u) => {
let post = get_post(&post_db, u.id);
// the post may or may not exist
match post {
// here, we know that both user and post exist
Some(p) => println!("post: {:?}", p),
None => println!("post not found"),
}
},
None => println!("user not found"),
}
}
main();post: Post { user_id: 1, title: "Hello, world", content: "This is my first post" }Let pattern matching
Well, the code looks quite long, it can be simplified using the let pattern matching. let does pattern matching and binding at the same time.
fn main() {
let user_db =vec![User {
username: "levi".to_string(),
id: 1,
}];
let post_db = vec![Post {
user_id: 1,
title: "Hello, world".to_string(),
content: "This is my first post".to_string(),
}];
let user = get_user(&user_db, 1);
// do pattern matching
if let Some(u) = user {
// user is Some, so we can get the user id
let post = get_post(&post_db, u.id);
if let Some(p) = post {
println!("post: {:?}", p);
} else {
println!("post not found");
}
} else {
// user is not Some
println!("user not found");
}
}
main();post: Post { user_id: 1, title: "Hello, world", content: "This is my first post" }and_then
Hmm, still too long, can it be shorter? Yes! Using and_then:
fn main() {
let user_db =vec![User {
username: "levi".to_string(),
id: 1,
}];
let post_db = vec![Post {
user_id: 1,
title: "Hello, world".to_string(),
content: "This is my first post".to_string(),
}];
let user = get_user(&user_db, 1);
// no more pattern matching!
let post = user.and_then(|u| get_post(&post_db, u.id));
match post {
Some(p) => println!("post: {:?}", p),
None => println!("user/post not found"),
}
}
main();post: Post { user_id: 1, title: "Hello, world", content: "This is my first post" }How does and_then work?
and_then is actually pretty simple. It takes a function that returns an Option.
If the value is None, it will return None. If the value is Some, it will return the result of the function applied to the value.
This pattern is very common in functional programming. It’s part of railway-oriented programming (ROP).
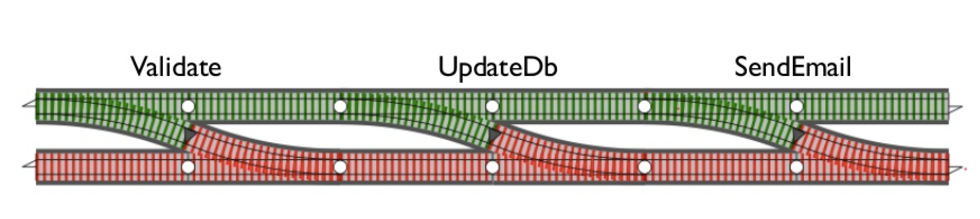
Let’s say we have:
x = Some(5)
f: i32 -> Option<i32>
g: i32 -> Option<i32>We can chain, x, f, and g using and_then like this:
x.and_then(f).and_then(g)and_then unwraps the Option and applies the function. If the value is None, it will return None immediately.
Here is a simple implementation of and_then:
fn and_then<A, B, F>(x: Option<A>, f: F) -> Option<B>
where
F: Fn(A) -> Option<B>,
{
match x {
// unwrap the value and apply the function
Some(x) => f(x),
None => None,
}
}
fn main() {
let a = Some(1);
let b = and_then(a, |x| Some(x + 1));
println!("{:?}", b);
}
main();Some(2)We will discuss about and_then in more detail in the next lesson, for now just remember that it’s a way to chain Option together
Null Pointer Exception
Why do we bother to use Option instead of just using null?
Let’s rewrite the code in Golang 😈
package main
import "fmt"
type User struct {
Username string
ID int
}
type Post struct {
UserID int
Title string
Content string
}
func getUser(userDB []User, id int) *User {
for _, u := range userDB {
if u.ID == id {
return &u
}
}
return nil
}
func getPost(postDB []Post, id int) *Post {
for _, p := range postDB {
if p.UserID == id {
return &p
}
}
return nil
}
func main() {
userDB := []User{
{
Username: "levi",
ID: 1,
},
}
postDB := []Post{
{
UserID: 1,
Title: "Hello, world",
Content: "This is my first post",
},
}
// get unexist user ID
user := getUser(userDB, 2)
// let's say we forget this:
// if user == nil {
// fmt.Println("User not found")
// return
// }
post := getPost(postDB, user.ID)
fmt.Println(post.Title)
}What’s the output? 😏
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x2 addr=0x10 pc=0x100becb94]
goroutine 1 [running]:Ooops panic!
The panic occurs because the getUser function returns nil (nil.ID raise panic) and we forgot to handle that case.
In Rust, this code won’t even compile! Saving you from the headache of debugging null pointer exceptions in production
Result
Another handy type is Result. It’s similar to Option, but it can also store an error message. It’s useful when we want to return an error message when something goes wrong (instead of just returning None).
It’s named Either in Haskell. Let’s try implementing it in Rust
// generic type is usually used
// for simplicity we will use i32 and String
enum Either {
// Left is to indicate an error
Left(String),
Right(i32),
}
fn divide(numerator: i32, denominator: i32) -> Either {
if denominator == 0 {
Either::Left("cannot divide by zero".to_string())
} else {
Either::Right(numerator / denominator)
}
}
fn main() {
match divide(10, 2) {
Either::Right(value) => println!("result: {}", value),
Either::Left(message) => println!("{}", message),
}
match divide(10, 0) {
Either::Right(value) => println!("result: {}", value),
Either::Left(message) => println!("{}", message),
}
}
main();result: 5
cannot divide by zeroLeft is for error, Right is for success
So why is it useful? Let’s see an example in another language
Error Pipeline in Golang
package main
import (
"errors"
"fmt"
"math"
)
func getSquareRoot(x float64) (float64, error) {
if x < 0 {
return 0, errors.New("cannot calculate square root of negative number")
}
return math.Sqrt(x), nil
}
func doubleValue(x float64) (float64, error) {
if x > 1000 {
return 0, errors.New("input too large")
}
return x * 2, nil
}
func convertToString(x float64) (string, error) {
if x > 500 {
return "", errors.New("value too large to convert to string")
}
return fmt.Sprintf("%.2f", x), nil
}
func processValue(x float64) (string, error) {
sqrt, err := getSquareRoot(x)
if err != nil {
return "", err
}
doubled, err := doubleValue(sqrt)
if err != nil {
return "", err
}
str, err := convertToString(doubled)
if err != nil {
return "", err
}
return "Result: " + str, nil
}
func main() {
result, err := processValue(16)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(result)
}That’s a lot of if err != nil! 😮💨
Error Pipeline in Rust
use std::fmt;
#[derive(Debug)]
enum MathError {
NegativeSquareRoot,
InputTooLarge,
ValueTooLarge,
}
impl fmt::Display for MathError {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
match self {
MathError::NegativeSquareRoot => write!(f, "cannot calculate square root of negative number"),
MathError::InputTooLarge => write!(f, "input too large"),
MathError::ValueTooLarge => write!(f, "value too large to convert to string"),
}
}
}
fn get_square_root(x: f64) -> Result<f64, MathError> {
if x < 0.0 {
return Err(MathError::NegativeSquareRoot);
}
Ok(x.sqrt())
}
fn double_value(x: f64) -> Result<f64, MathError> {
if x > 1000.0 {
return Err(MathError::InputTooLarge);
}
Ok(x * 2.0)
}
fn convert_to_string(x: f64) -> Result<String, MathError> {
if x > 500.0 {
return Err(MathError::ValueTooLarge);
}
Ok(format!("{:.2}", x))
}
fn process_value(x: f64) -> Result<String, MathError> {
// pattern match the Result
let sqrt_result = match get_square_root(x) {
Ok(sqrt_result) => sqrt_result,
Err(err) => return Err(err),
};
let doubled_result = match double_value(sqrt_result) {
Ok(doubled_result) => doubled_result,
Err(err) => return Err(err),
};
let string_result = match convert_to_string(doubled_result) {
Ok(string_result) => string_result,
Err(err) => return Err(err),
};
let final_result = format!("Result: {}", string_result);
Ok(final_result)
}
fn main() {
let input = 16.0;
match process_value(input) {
Ok(result) => println!("{}", result),
Err(err) => println!("Error: {}", err),
}
}
main();Result: 8.00Wow, a lot of pattern matchings! Can we simplify it?
and_then to the rescue again!
Remember and_then from the Option type? We can use it here!
fn process_value(x: f64) -> Result<String, MathError> {
get_square_root(x)
// if `get_square_root` returns an error, it will be returned as the final result
// otherwise the result will be passed to `double_value`
.and_then(double_value)
.and_then(convert_to_string)
.map(|string_result| format!("Result: {}", string_result))
}
main();Result: 8.00In the context of Result, and_then is used to chain together functions that return a Result. It will return Err immediately if the value is Err, otherwise it will return the result of the function applied to the value.
Again, we will discuss about and_then in more detail in the next lesson, for now just remember that it’s a way to chain Result together
? operator
The ? operator in Rust is a shorthand for the match expression when working with Result. It is used to simplify error handling & propagation in a concise and readable way.
The ? operator does the following:
- If the
ResultisOk(value), the?operator unwraps the value and allows the execution to continue with the unwrapped value. - If the
Result is Err(error), the?operator immediately returns the error from the current function, propagating it to the caller.
…which was exactly what we implemented before!
fn process_value(x: f64) -> Result<String, MathError> {
let sqrt_result = get_square_root(x)?; // notice the `?` operator
// the same as
// let sqrt_result = match get_square_root(x) {
// Ok(value) => value,
// Err(err) => return Err(err),
// };
let doubled_result = double_value(sqrt_result)?; // also has `?`
let string_result = convert_to_string(doubled_result)?; // also has `?`
Ok(format!("Result: {}", string_result))
}
main();Result: 8.00Algebraic?
Now the interesting part. Why is called “algebraic” data type?
Because we can think of them as solutions to algebraic equations. For example, we can think of a tuple as a solution to the equation A * B. And we can think of a sum type as a solution to the equation A + B.
Then, algebraic rules apply (addition, substraction, multiplication, etc). For example:
struct Item {
x: i32, // -> i32
y: i32, // -> i32
color: Color, // -> Color = 3
} // i32 * i32 * 3
enum Color {
Red, // -> 1
Green, // -> 1
Blue, // -> 1
} // -> 1 + 1 + 1 = 3The cardinality of Item is i32 * i32 * 3
If we refactor the Item’s x and y into a Point struct, then the cardinality of Item is Point * Color, which is (i32 * i32) * 3
Since multiplication is associative, we can also think of it as (i32 * i32) * 3, which is the same as i32 * i32 * 3
struct Point {
x: i32, // -> i32
y: i32, // -> i32
} // i32 * i32
struct Item {
point: Point, // -> i32 * i32
color: Color, // -> Color = 3
} // i32 * i32 * 3 (still the same)Refactoring based on Algebraic Rules
Let’s study this function
func get_user(user_id int) (*User, error) {
if user_id == 1 {
return &User{username: "levi", id: 1}, nil
} else {
return nil, errors.New("user not found")
}
}It’s common in Golang to return an error as the last return value.
Since *User and error can be nil and the return type is a product type of them, the cardinality of the return value is (1 + U) * (1 + E) where U is the cardinality of *User and E is the cardinality of error
| *User | error | cardinaility | note |
|---|---|---|---|
| user | nil | U * 1 | Ok |
| user | error | U * E | Invalid, if user is not nil, error must be nil |
| nil | error | 1 * E | Ok |
| nil | nil | 1 * 1 | Invalid, if user is nil, then error must be not nil |
Notice that two possible values are invalid (aren’t them?). So let’s substract those cardinalities
(1 + U) * (1 + E) - (U * E) - (1 * 1)
(1 + U + E + UE) - UE - 1
U + EInterestingly U + E is the cardinality of Result<User, Error> in Rust
So the above code is actually equals to:
fn get_user(user_id: i32) -> Result<User, Error> {
...
}with invalid states removed!
PS, Golang won’t reject this:
return &User{username: "levi", id: 1}, errors.New("user not found")or this
return nil, nilMore Examples
More examples can be found in this excellent article